Introducing Conveyor

Conveyor is a tool for plugging in various data types and sources into Elasticsearch. The open-source products offered by Elasticsearch are top notch. Though often used in the areas of server logging and searching, we found a much greater potential. Through multiple iterations of working with Elasticsearch’s primary data input tools, (API, Logstash, and Beats) we decided to construct a tool that would drastically lower the complexity of inserting data into Elasticsearch.
We are now using Conveyor as a plugin inside of Kibana to quickly and easily import data from Microsoft SQL Server, text files, and other data sources. But, we’re just getting started with creating additional sources. We are confident that if you need to get data into Elasticsearch, you can utilize Conveyor for an easy import method. You can check to see if a source has already been created for the data you have. Or, you can help us build an even better product and community by contributing a new source.
Keep reading to find out how Conveyor works, or skip to the installation docs to give it a try today.
Important Terms
Before we dive into how it works, lets define some important terms.
- Channels - These are the data connections that you have created. They either have, are, or are ready to receive data and pipe it into Elasticsearch. They are created from sources. In programming lingo, they could be considered instances of a specific source.
- Sources - These are templates authored for ease of use; each generally targets a specific data source or import method. In programming lingo, these would be classes.
- Parameters - These are placeholders in the
sources which will be replaced when you create a channel. Think of them as inputs to a function or parameters for a database connection.
How It Works
Conveyor is an orchestration tool and at its core is an API that talks to Elasticsearch and Node-RED. To make interaction with Conveyor even easier and enhance the user experience, we have also built a plugin that works inside of Kibana. The combination of the Conveyor API, Conveyor Plugin, Node-RED, Kibana, and Elasticsearch make up the entire system.
System Overview
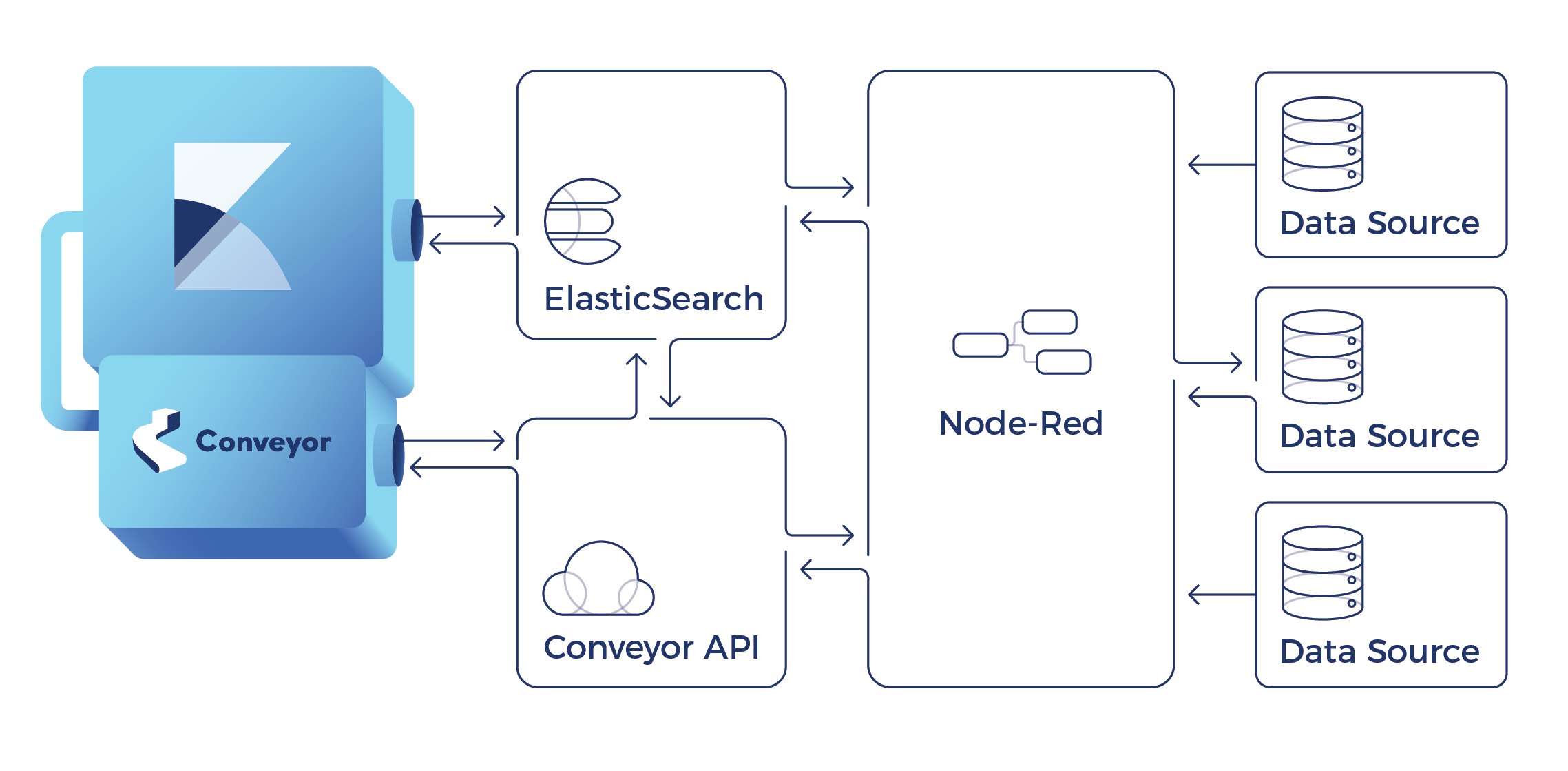
System Components
- Elasticsearch - This is the data store. It holds the definitions of the sources, the channels, and logs interactions with the Conveyor API. It is also the primary store for data being imported through Channels.
- Kibana - Kibana stands alone as an amazing tool for managing Elasticsearch. As a fully open source offering, it packs some amazing data visualizations and query tools. Add on its premium features and it becomes a powerful analytical tool for alerts, anomaly detection, and advanced user management.
- Conveyor Plugin - The plugin is the primary interface with the Conveyor Node. Within it, you can easily create, delete, and edit the channels you have built to bring data into Elasticsearch.
- Conveyor Node - This node is an API, which acts as an orchestration engine. It knows how to combine user provided parameters with developer created Sources to build Node-RED flows. It also proxies data connections into Node-RED.
- Node-RED - This is the foundation on which Conveyor is built. Node-RED is an amazing tool for rapid development prototyping, IoT connectivity, and many other tasks. Its visual builder is often easier to understand for non-developers but can be frustrating for anyone not working with it frequently. Conveyor leverages its Robust API for scripting the management of flows, which are the foundation of how Node-RED works. Though drawn seperately, Node-RED runs inside the Conveyor Node.
- Datasources - These you provide. Do you have a CSV file that you would like to quickly upload into Elastisearch? Or do you need some SQL Server data monitored by Elastics Watcher or Machine Learning tools? With Conveyor getting your data sources connected to Elasticsearch your data has never been easier to play around with.
Basic Workflow
- A Developer or Author Creates a Source
A source or data source can be thought of as a template. In fact, a data source uses a templating language to achieve some of its functionality. Imagine a statement for extracting data from SQL Server. Verbally it would go like this:
Execute the query Select * from dbo.sales_orders on Company-SQL-Server every 3 minutes
But written as a template using the Mustache templating language it might look like this:
Execute the query {{query}} on {{server}} every {{timing}}
This is very similar to how a source works except that rather than templating a sentence, they are templating a Flow inside of Node-RED. For more details on this section of the workflow start with the Basics of Authoring
- A Kibana User Provides Parameter Values to Create A Channel
Each of the above templated values are considered parameters. Parameters can be anything from strings and numbers to files. They are input into the + Create screen in the Conveyor plugin inside of Kibana.
Once these values are submitted, the Conveyor API combines them with the source from above to create a customized Node-RED flow. Inside of Conveyor this is considered a Channel.
- Data is Supplied to the Channel
Now that we’ve created a fully customized channel, we supply data to it and the channel inserts it into Elasticsearch. How it is inserted, the rate, the index, etc is largely controlled by the Source design mentioned above and the parameters provided.