Basic of Source Authoring
Having many Sources and having quality sources is paramount to the Conveyor product. Both quality and quantity improve the ease at which a user can get data into Elasticsearch using Conveyor. As such, we’re going to walk through how to create sources and some best practices when doing so.
Node-RED
To get started authoring your own Sources, you’ll first need an understanding of Node-RED. If you haven’t used it before then check out this quick and fun tutorial I wrote for it. A Fun Introduction to Node-RED. We’re working on a Conveyor specific tutorial so stay tuned.
Here is what the basic Node-RED interface looks like. If you’re running Conveyor with the compose provided Node-RED should be available at http://localhost:1880
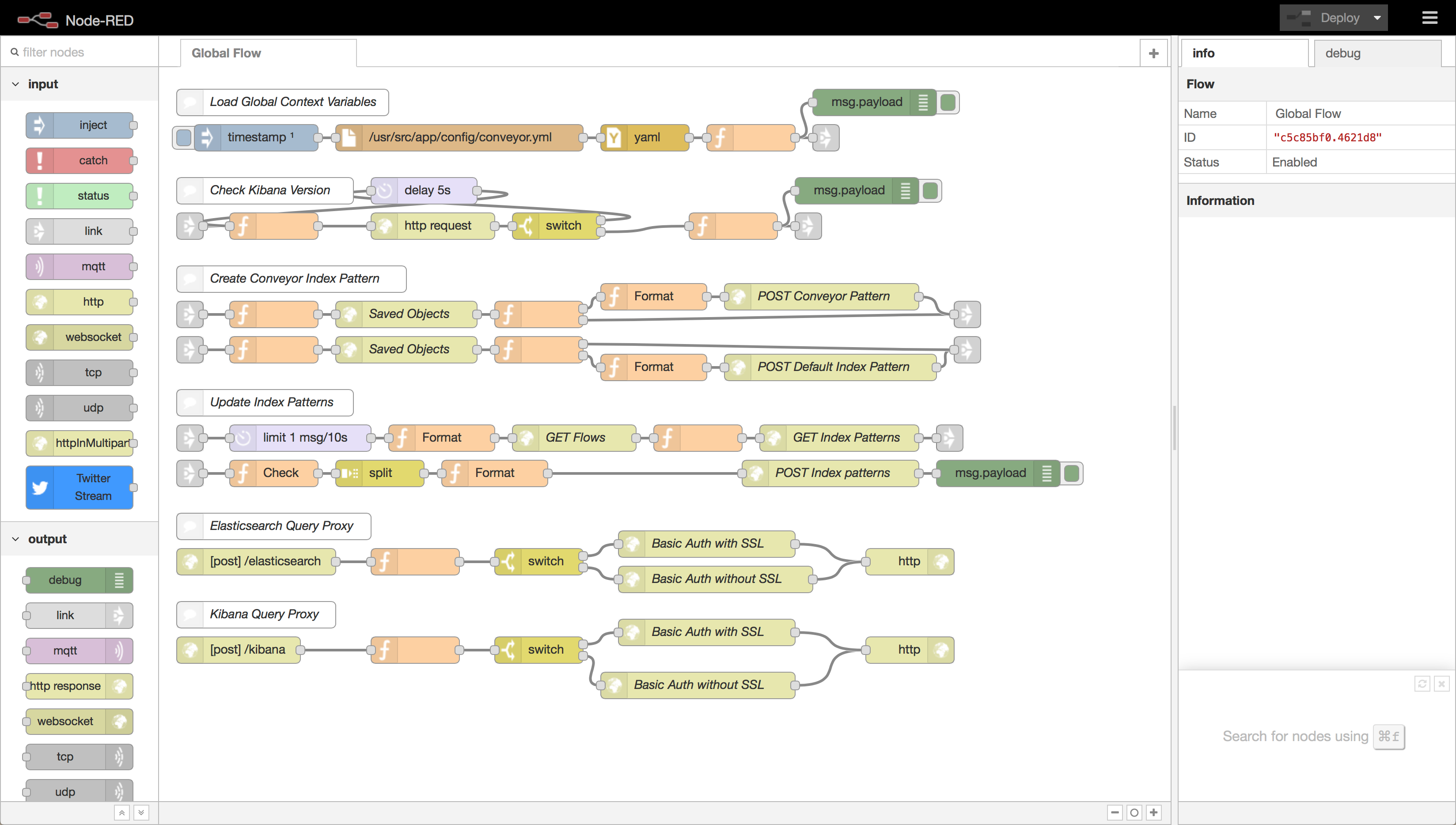
The flow showing is a special flow called the Global Flow it contains a lot of the connection management and some startup tasks. Normally you wont modify it, but it provides a good idea of what a flow looks like.
On the left you have a list of available nodes, the center contains the flow or where the flow will go, and the right contains an info and debug panel. To create a flow you drag nodes onto the flow and connect them. For more detail see the above tutorial. Once you geel comfortable with node-RED let’s create a source.
Creating your own Source
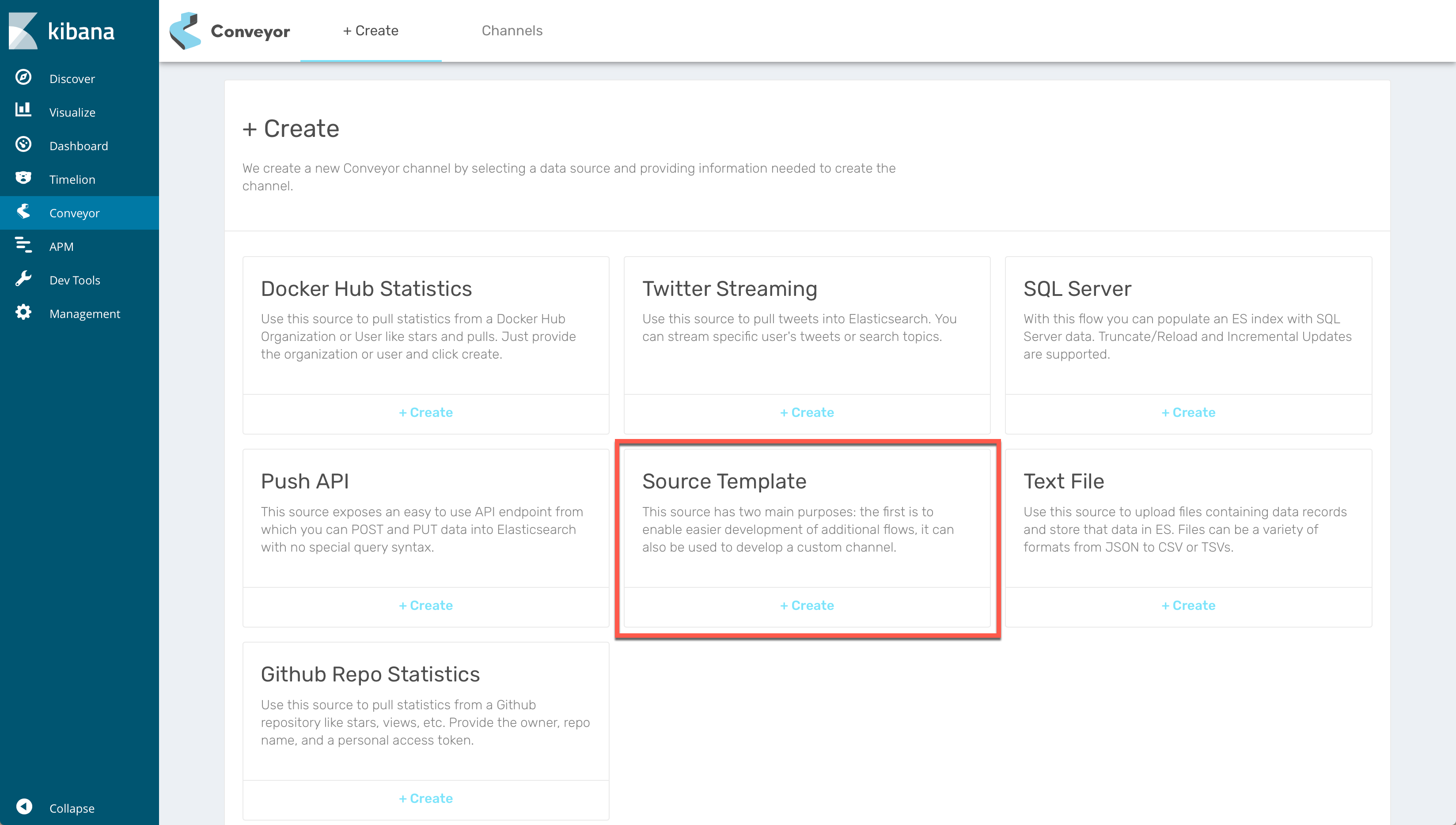
From the Kibana interface create a channel from the Source Template. This is a source we’ve created to help you get started.
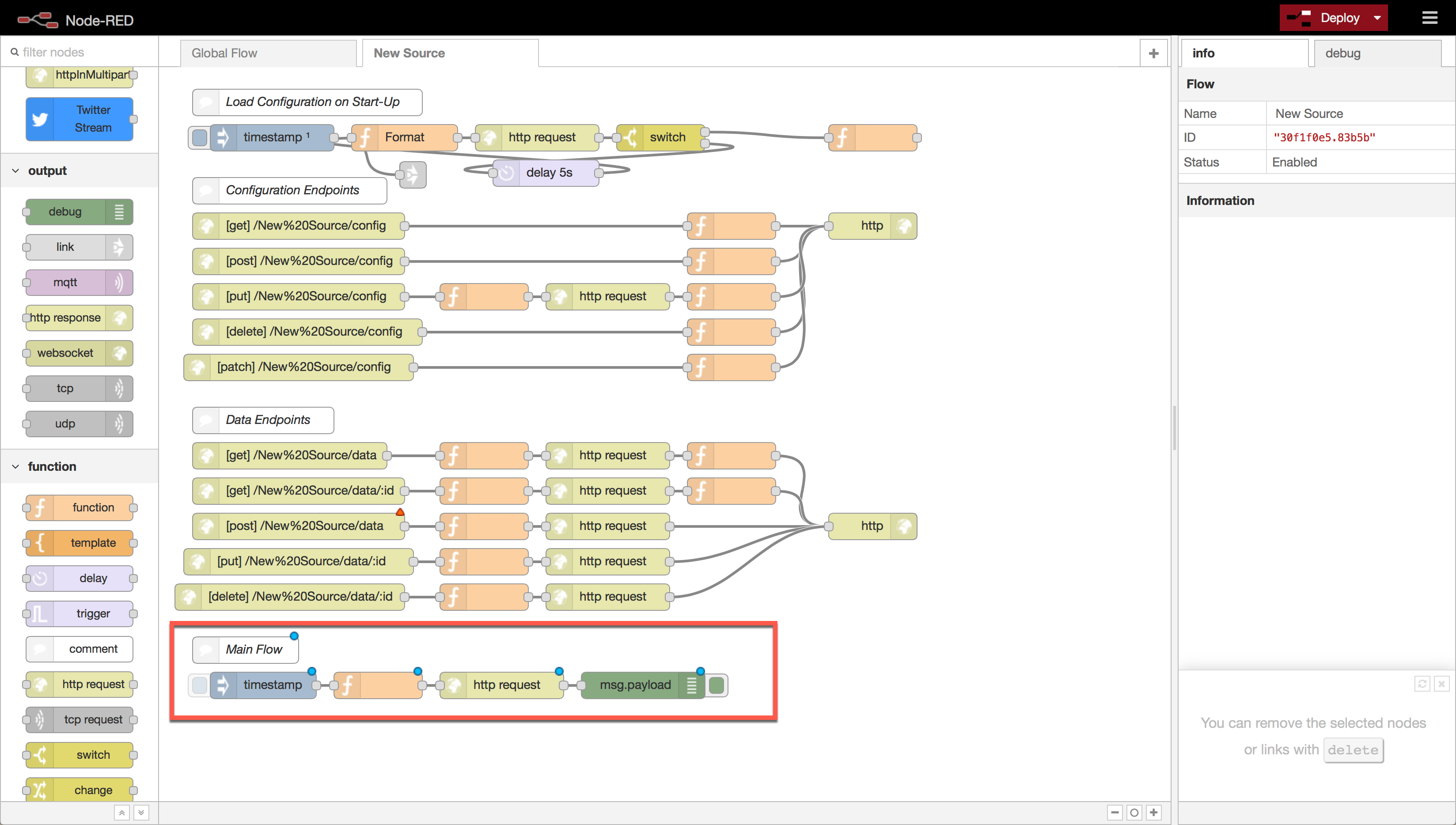
Now go to the Node-RED interface and change tabs inside Node-RED to the channel you created. This is the source tempalte flow. Let’s break it down.
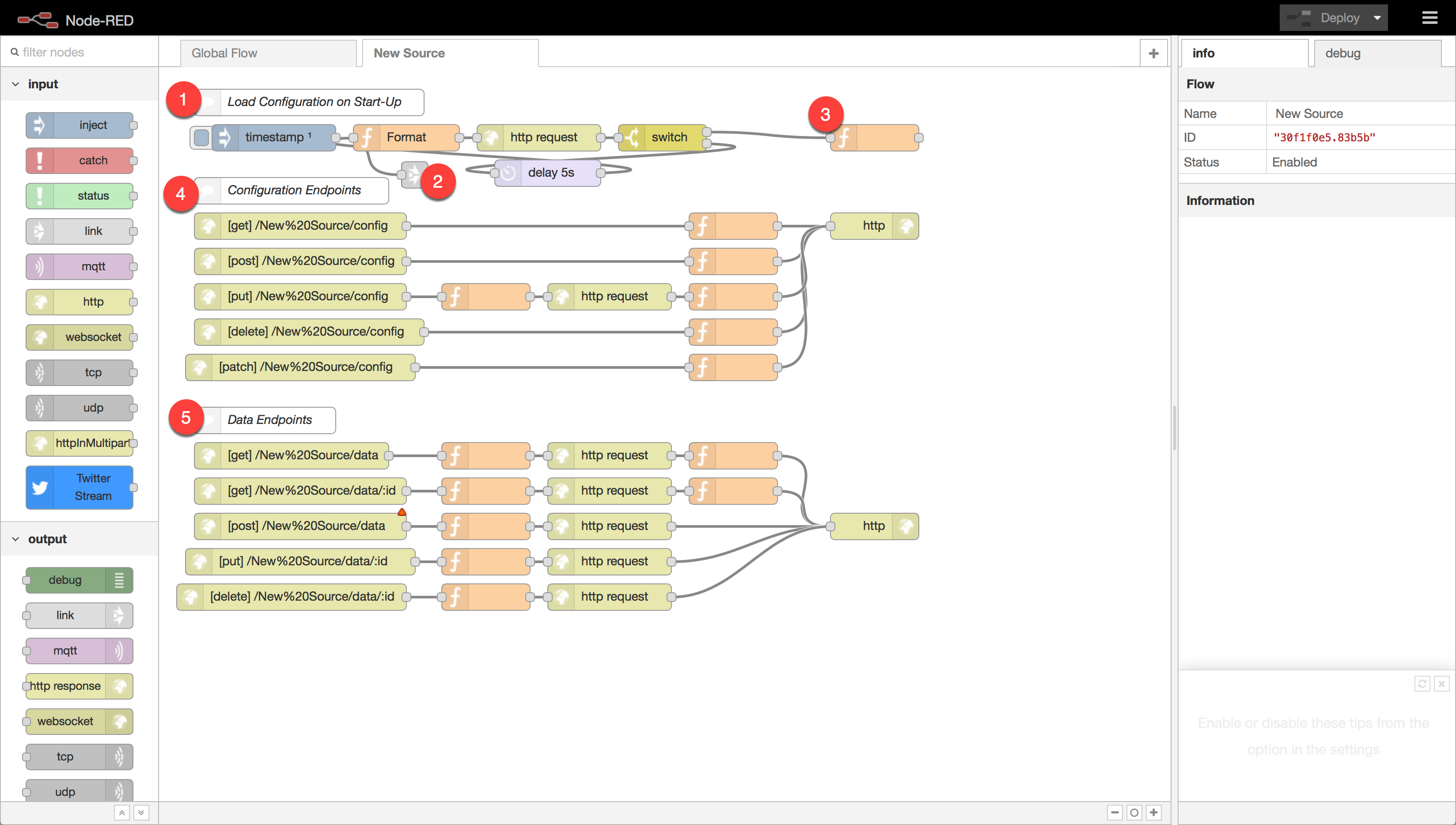
- This Load Configuration section executes once everytime the flow is started. This occurs when the server starts, but also when the flow is created. There are a couple of things it does for you.
- Triggered on startup, this link node jumps to the Global Flow and create the index patterns for the channel.
- The section of flow leading up to this and this function node GET the flow parameters and load them into the flow context.
- The Configuration Endpoints section exposes endpoints for GETing and PUTing the configuration variables. If the flow is designed for it, this allows modifying channel parameters even after the flow has been created.
- The Data ndpoints section exposes a way to query the underlying Elasticsearch data through a friendly Channel Specific API.
A demonstration
For a quick demonstartion I am going to create a new source that inserts data into Elasticsearch everytime we push a button in the Node-RED interface. Not super useful, but it will show the basic task of getting data into ES.
We’re going to need to drag 4 nodes onto the screen in the area below the Data Endpoints section:
- An injext node
- A function node
- A HTTP Request node
- A Debug node
See below for what my small flow looks like.